Data extraction
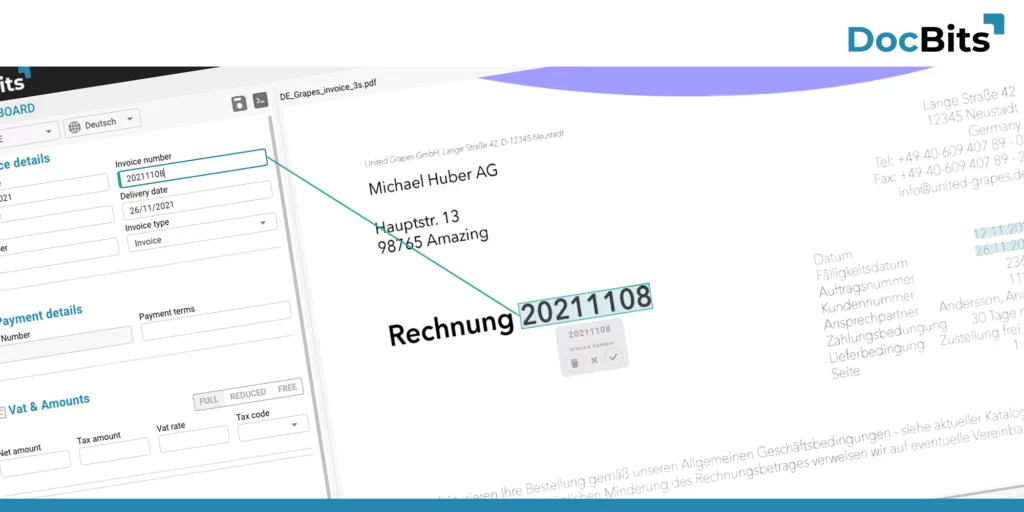
In today’s world, which is characterized by a wealth of data, the analysis and further use of data is an omnipresent topic. In this context, the extraction of data from a wide variety of documents plays an indispensable and constantly necessary role.
UI for Data Validation

Almost all business processes begin, include or end with a document. So companies tend to sit on a pile of data. Of which, 80% is unstructured.