DocBits Integration to Infor

DocBits is the newest document capturing software and solution developed by FELLOWPRO and it’s a completely AI and cloud-based solution
DocBits Demo
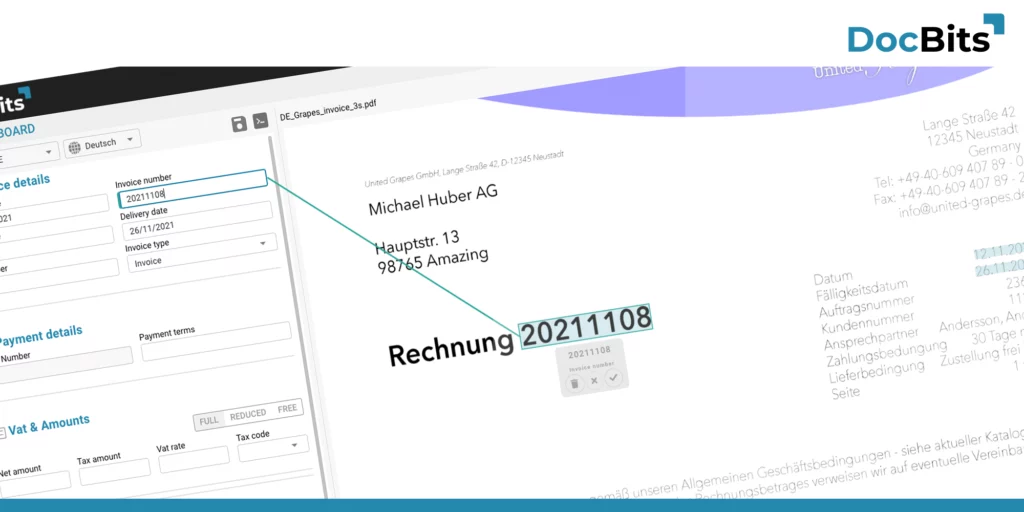
DocBits Integration with Infor IDM and Infor LN or Infor M3 – Infor OS makes it easy to integrated other application.