How DocBits Enhances Efficiency in Infor LN + M3 PO Matching
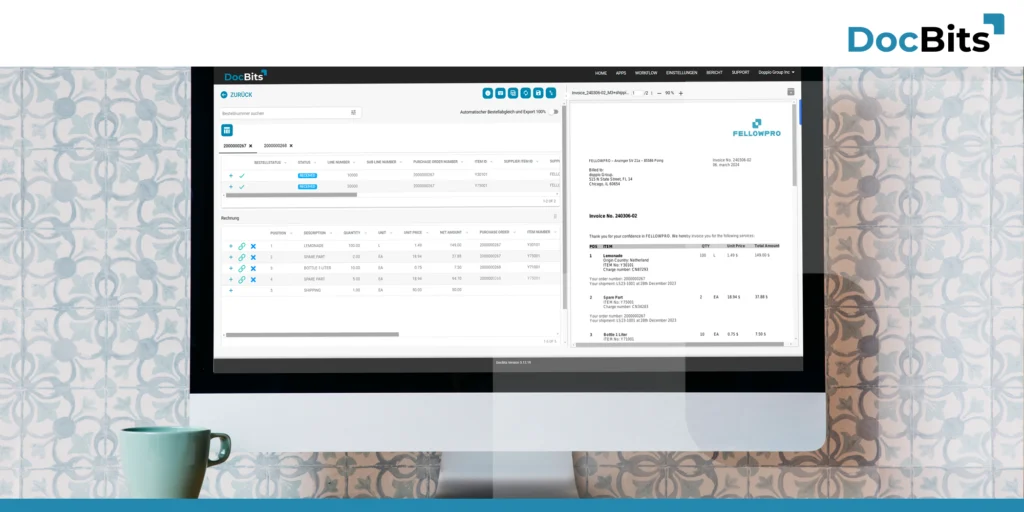
In the contemporary landscape of enterprise resource planning (ERP), efficiency is key, especially in the realms of Infor LN and M3 for Purchase Order (PO) matching. This is where DocBits, a cutting-edge solution by FellowPRO AG, comes into play
Optimise the way your company works with AI software!

In the dynamic world of entrepreneurship, time is money and the right technology can make the difference between a thriving business and inefficient operations.
AI: The Game-Changer for Infor ERP Documents

The dawning of artificial intelligence (AI) is transforming the realm of enterprise resource planning (ERP) systems. A testament to this evolution is AI’s integration into Infor ERP’s document management.
A look into the world of Deep Learning

In today’s digital world, where data is abundant, Artificial Intelligence (AI) plays a crucial role. Under the broad umbrella of AI, there is a specific and powerful technology called Deep Learning.
What is Document Understanding?

In a world where data is the new gold, the ability to use information efficiently is critical to business success. However, much of this data is hidden in
documents that exist in unstructured or semi-structured form.
What is Intelligent Document Processing?
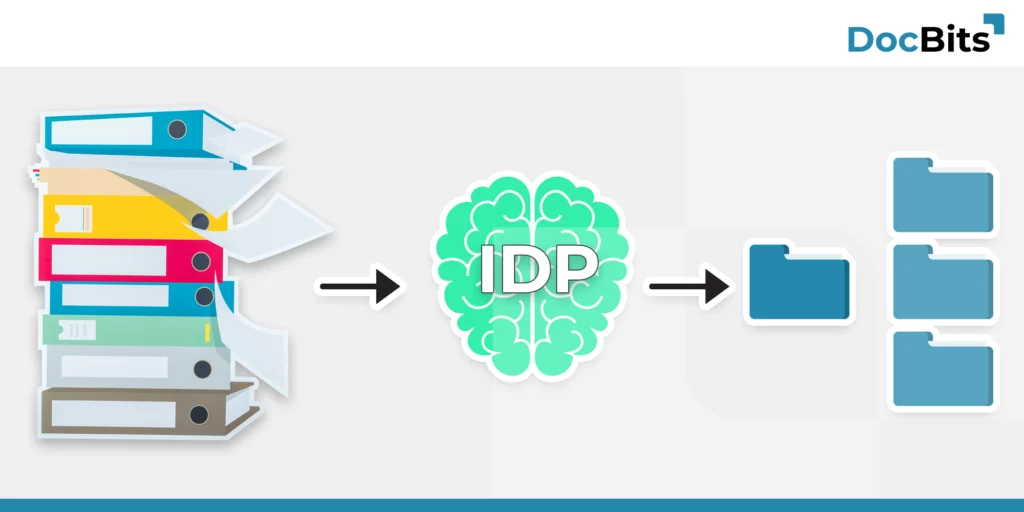
In the modern business world, documents are omnipresent. From invoices to contracts, the flood of paperwork can be overwhelming. But what if you could convert this unstructured data into valuable, usable information?
What do we understand by OCR?

In a digitized world, processing information quickly and accurately is critical. OCR, or Optical Character Recognition, plays an important role in this. But what exactly is OCR and how does it work?
When is a program intelligent?

The question of when a program can be considered “intelligent” is particularly relevant in today’s world, where AI and machine learning are becoming increasingly important. To be considered intelligent, systems essentially need three things:
The future is now
Artificial intelligence in everyday life and its various facets.In a world that is constantly evolving, AI has become an important part of our everyday lives.
Efficient invoice processing with DocBits

Efficient invoice processing with DocBits Simplify your document processing with AI Invoice processing is a time-consuming and tedious task that is a major challenge in many businesses. Not only can manually capturing, reviewing, and processing invoices take a lot of time, but it can also lead to human error. After all, as the saying goes, […]