The extraction of data from PDFs and scanned documents might not be the most interesting or challenging issue of the century. It doesn’t give you the opportunity to control a robot, play virtual games or helps you express your creativity. Instead, it’s plain diligent work, something that “KI” promised to automate but hasn’t achieved yet. Nonetheless, the processing of documents, meaning the conversion of analogue data into a digital format, describes a subtle challenge – a complex task, that is so easy and yet so difficult to resolve.
Document processing with DocBits Version 2.0, the conversion of analogue data into a digital format – an easy and yet so difficult task to resolve.
We at FELLOW PRO AG realized after completing several different projects, that document processing is omnipresent – from companies to non-governmental organizations, from little businesses to large corporations – there is always a PDF that needs to be digitalised!
The processing of documents is therefore not just difficult, it might also be in urgent need.
This blog post explains the framework for the development of document processing solutions and describes what we are working on for DocBits Version 2.0.
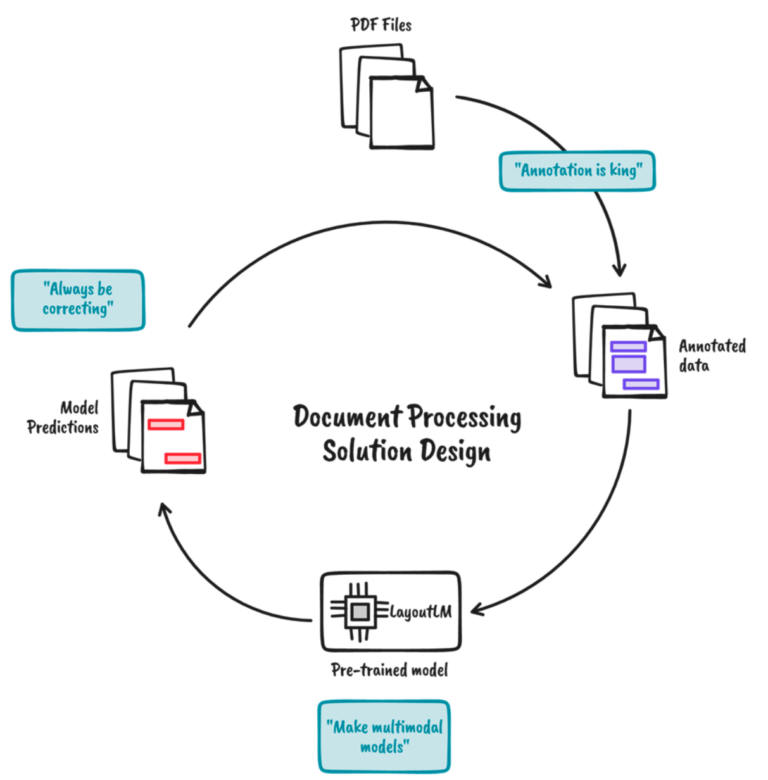
Document processing with DocBits Version 2.0 is based on the principles:
Annotations are indispensable: There is no simple nostrum. Even if you have a good model, you still must make sure to fine tune your data. Ideally you should have an annotation tool with integrated fine-tuning, or you are flexible enough to integrate the mechanism.
Generate multi-modal models: When analysing a document, we are not just relying on the text. Instead, we are taking all information (position, font size, etc.) as context, to make use of all these attributes. A plain OCR (optical character recognition) or a simple text-based approach is insufficient to resolve this task.
Always correct. OCR– and document layout models are not always perfect, hence the necessity for humans to correct the results in the system. The correction can be used to train your model or as the penultimate step before saving the results to a database.
Understanding the form
All the above-mentioned principles have been considered in DocBits. The document describes the typical document processing workflow:
Annotations are indispensable
Labels are indispensable for every solution in document processing. Documents tend to be very diverse, even if they have distinguishable patterns. A tool for reliable document labelling is therefore required.
Generation of multi-modal models
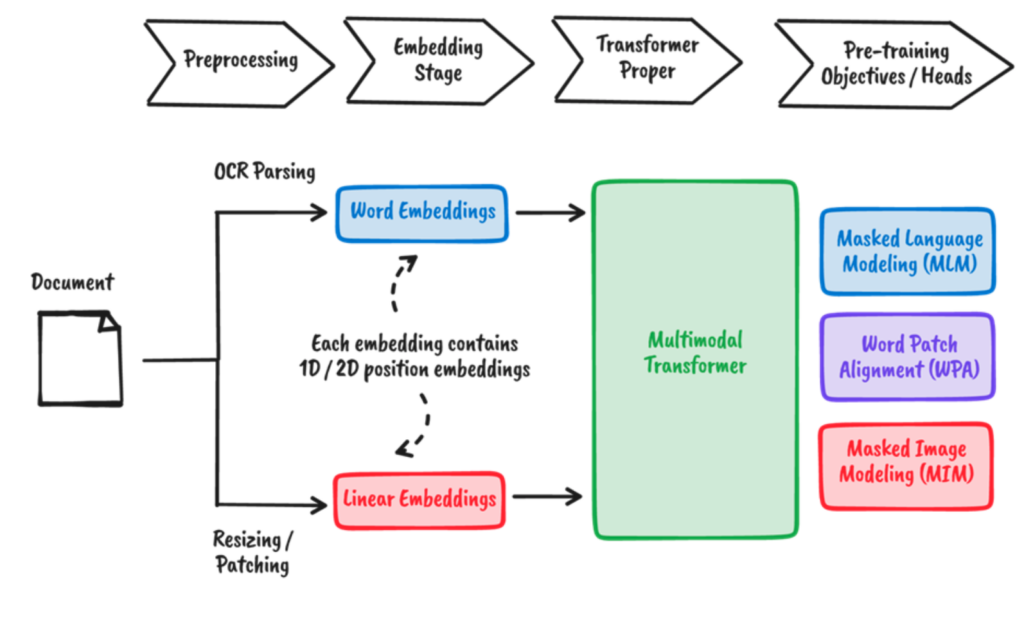
An additional reason why processing of documents is such an attractive problem lies in its multi-modal nature – textural and visual information is readily available. Unfortunately, rough solutions for document processing tend to only use one or the other:
Image centred approaches involve a lot of complex business rules around the frame of limitation and text placement to obtain the required information. They often rely on templates that aren’t scalable. Text centred approaches are based on NLP-pipelines for OCR-captured texts. However, text blocks are not compatible with the domain where these models were originally trained, leading to a mediocre performance.Fortunately, multi-modal models like DocBits have the ability to learn from textural and visual information. Not only word and image itself, but also their positions are embedded for a certain document. The interactions between them are then learned, aided by predefined training goals.
The DocBits model learns from textual as well as visual information and learns about the interaction between them.
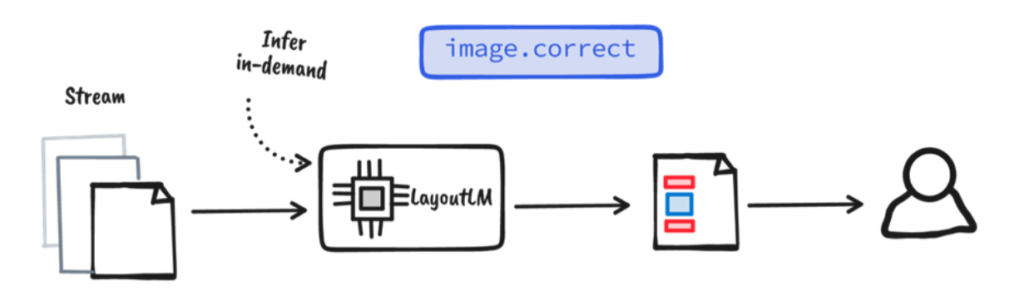
Always correct
We think that even with the most efficient document processing systems, human knowledge and experience for corrections and assessment must be incorporated. Human-in-the-loop can serve as a final inspection for the output of a model. We can reuse the corrected annotations to further refine the model and close the loop.
Final remarks for document processing with DocBits Version 2.0
This blog post gives an outlook on our Version 2.0, describing the most important aspects of a document processing solution: an annotation mechanism, a multi-modal model and a step for assessment.
Machine learning was promised to automate manual labour. However, it looks like we hit a wall and instead started to automate creative works. In my opinion, we have optimised the search for nostrums: a big model is fed with input to receive the desired output. Manual labour, such as the processing of documents, is not like that. Instead, they are generally custom-made: you must label the data, make sure all elements of the document are incorporated and correct the output of the models – and one big model does not suffice. There are several models, extracting different things.
In the contemporary landscape of enterprise resource planning (ERP), efficiency is key, especially in the realms of Infor LN and M3 for Purchase Order (PO) matching. This is where DocBits, ...
In the intricate world of Purchase Order (PO) matching, overcoming challenges efficiently and accurately is crucial for any business’s financial health. This case study explores how DocBits, an innovative solution ...
In the dynamic world of entrepreneurship, time is money and the right technology can make the difference between a thriving business and inefficient operations.
In the realm of financial operations, the efficiency and accuracy of Accounts Payable (AP) processes are critical for the health and success of any business.
Navigating the intricacies of Infor ERP document management requires a tool that’s both precise and efficient. Enter DocBits — a beacon of innovation in AI swarm intelligence that transforms PO ...
In the ever-changing business world, efficiency is the key to success. Companies are looking for innovative solutions to optimise their processes and increase their productivity.