Was ist Intelligent Document Processing?
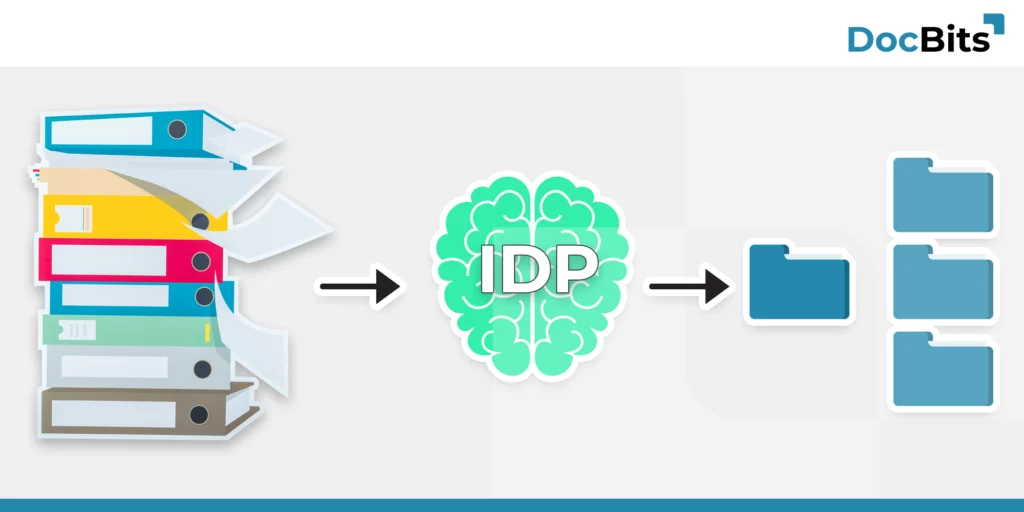
In der modernen Geschäftswelt sind Dokumente omnipräsent. Von Rechnungen bis zu Verträgen kann die Flut an Papierkram überwältigend sein. Doch was, wenn man diese unstrukturierten Daten in wertvolle, nutzbare Informationen umwandeln könnte?
Effiziente Rechnungsverarbeitung mit DocBits

Effiziente Rechnungsverarbeitung mit DocBits Vereinfachen Sie Ihre Dokumentenverarbeitung mit KI Die Rechnungsverarbeitung ist eine zeitaufwändige und mühsame Aufgabe, die in vielen Unternehmen eine große Herausforderung darstellt. Die manuelle Erfassung, Prüfung und Verarbeitung von Rechnungen kann nicht nur viel Zeit in Anspruch nehmen, sondern auch zu menschlichen Fehlern führen. Denn wie sagt man so schön: “Wir […]
Validierung

Definition und die Bedeutung für Unternehmen
Daten spielen für den Erfolg eines Unternehmens eine entscheidende Rolle und gerade in der heutigen digitalen Ära mehr denn je.
Die Revolution der Datenverarbeitung durch DocBits

In einer Welt, in der Daten zu einer der wertvollsten Ressourcen geworden sind, stehen Unternehmen zunehmend vor der Herausforderung, die Informationen, die sie sammeln, effektiv zu nutzen und schnellstmöglich zu verarbeiten.
Personalakte

Heutzutage wird in den meisten Unternehmen für jeden Mitarbeiter eine Personalakte geführt. Nicht etwa weil es Pflicht ist – nein – sondern weil es in beiderseitigem Interesse liegt.
Der Online-Handel lebt davon …

Ohne Bestellungen kann der Online-Handel nicht überleben. Aber auch in produzierende Unternehmen oder bei Dienstleistern sind Bestellungen an der Tagesordnung.
Nicht schon wieder eine Rechnung

Niemand bekommt gerne Rechnungen, das bedeutet ja, dass man Geld zahlen muss. Viel lieber ist man auf der anderen Seite und schreibt Rechnungen an andere und erhält dann Geld. Ist doch so, oder?
Datenextraktion
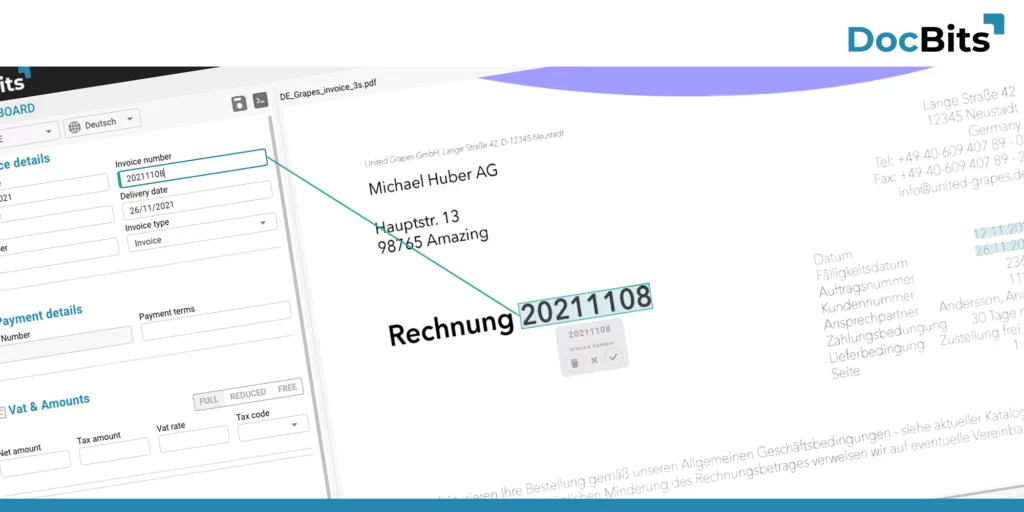
In der heutigen Zeit, die durch Datenreichtum geprägt ist, ist die Analyse und weitere Verwendung von Daten ein allgegenwärtiges Thema. Dabei spielt die Extraktion von Daten aus unterschiedlichsten Dokumenten eine unabdingbare und konstant notwendige Rolle.
Optimieren Sie Ihre Prozesse
Prozesse optimieren – Wer will das nicht? Gibt es eine Möglichkeit bestimmte Abläufe und Vorgänge im Unternehmen zu verbessern und erleichtern, wäre es ganz schön blöd, wenn man diese nicht nutzen würde.
Dokumentenverarbeitung mit DocBits Version 2.0

Die Extraktion von Informationen aus PDFs und gescannten Dokumenten ist vielleicht nicht die interessanteste oder herausforderndste Thematik des Jahrhunderts.