What is Intelligent Document Processing?
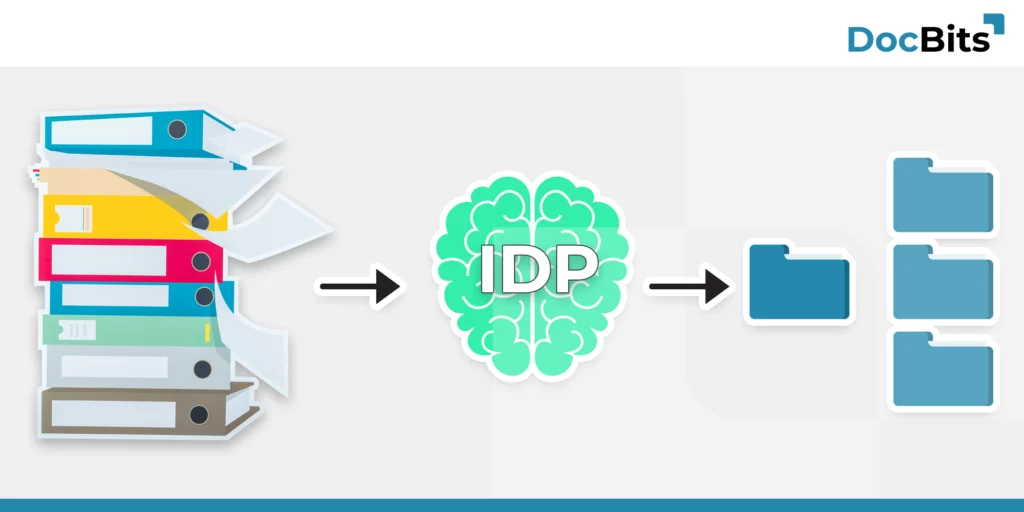
In the modern business world, documents are omnipresent. From invoices to contracts, the flood of paperwork can be overwhelming. But what if you could convert this unstructured data into valuable, usable information?
Efficient invoice processing with DocBits

Efficient invoice processing with DocBits Simplify your document processing with AI Invoice processing is a time-consuming and tedious task that is a major challenge in many businesses. Not only can manually capturing, reviewing, and processing invoices take a lot of time, but it can also lead to human error. After all, as the saying goes, […]
Document format

Document format What is it, which ones are there and what are they used for? The world of document processing has made tremendous strides in recent years. With the advent of artificial intelligence (AI), new ways of processing documents intelligently, efficiently and automatically have emerged. In businesses, documents play a central role, whether in administration, […]
Validation

Definition and the importance for companies: Data plays a critical role in the success of a business, and especially in today’s digital era more than ever.
How you can work with other companies to automate your document processing

How you can work with other companies to automate your document processing This might seem contradictory at first sight but it is really possible to optimize your processes by working in a community with other companies and even your competitors. This can be simply achieved by introducing swarmintelligence. So what does this term exactly mean? […]
Increased efficiency and competitive advantages

In today’s dynamic business environment, it is critical to continuously improve a company’s efficiency and productivity in order to remain competitive.
The revolution in data processing through DocBits

In a world where data has become one of the most valuable resources, companies are increasingly faced with the challenge of effectively using the information they collect and processing it as quickly as possible.
Personnel file
Today, in most companies a personnel file is kept for each employee. Not because it is obligatory – no – but because it is in the interest of both parties. In Germany, there is only an obligation to keep a personnel file in the public sector (authorities), but not in the private sector.
Online retail lives on it …

Without any order, online retail cannot survive. But orders are also the order of the day in manufacturing companies or for service providers. Orders are documents that companies either place or receive.
Not again an invoice

No one likes getting invoices, after all, that means paying money. Much rather be on the other side and write invoices to others and then receive money. Isn’t that right?